
具有多重共线性或相关特征的置换重要性¶
在本例中,我们使用 permutation_importance计算 Wisconsin乳腺癌数据集上的置换重要性。 RandomForestClassifier可以很容易地在测试数据集上获得97%的准确率。因为这个数据集包含多重共性特征,所以置换的重要性将显示没有一个特征是重要的。处理多重共线性的一种方法是对特征的Spearman秩序相关性进行分层聚类,选择一个阈值,并从每个聚类中保留一个特征。
Note: See also Permutation Importance vs Random Forest Feature Importance (MDI)
print(__doc__)
from collections import defaultdict
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import spearmanr
from scipy.cluster import hierarchy
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
from sklearn.model_selection import train_test_split
乳腺癌数据上的随机森林特征重要性
首先,我们在乳腺癌数据集上训练随机森林,并在测试集上评估其准确性:
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
print("Accuracy on test data: {:.2f}".format(clf.score(X_test, y_test)))
Accuracy on test data: 0.97
其次,我们绘制了基于树的特征重要性和置换重要性。置换重要性图显示,变换一个特征最多降低了0.012的准确性,这意味着没有任何一个特征是重要的。这与上面计算的高精度测试是矛盾的:某些特性必须是重要的。在训练集上计算置换的重要性,以显示模型在训练过程中对每个特征的依赖程度。
result = permutation_importance(clf, X_train, y_train, n_repeats=10,
random_state=42)
perm_sorted_idx = result.importances_mean.argsort()
tree_importance_sorted_idx = np.argsort(clf.feature_importances_)
tree_indices = np.arange(0, len(clf.feature_importances_)) + 0.5
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 8))
ax1.barh(tree_indices,
clf.feature_importances_[tree_importance_sorted_idx], height=0.7)
ax1.set_yticklabels(data.feature_names[tree_importance_sorted_idx])
ax1.set_yticks(tree_indices)
ax1.set_ylim((0, len(clf.feature_importances_)))
ax2.boxplot(result.importances[perm_sorted_idx].T, vert=False,
labels=data.feature_names[perm_sorted_idx])
fig.tight_layout()
plt.show()
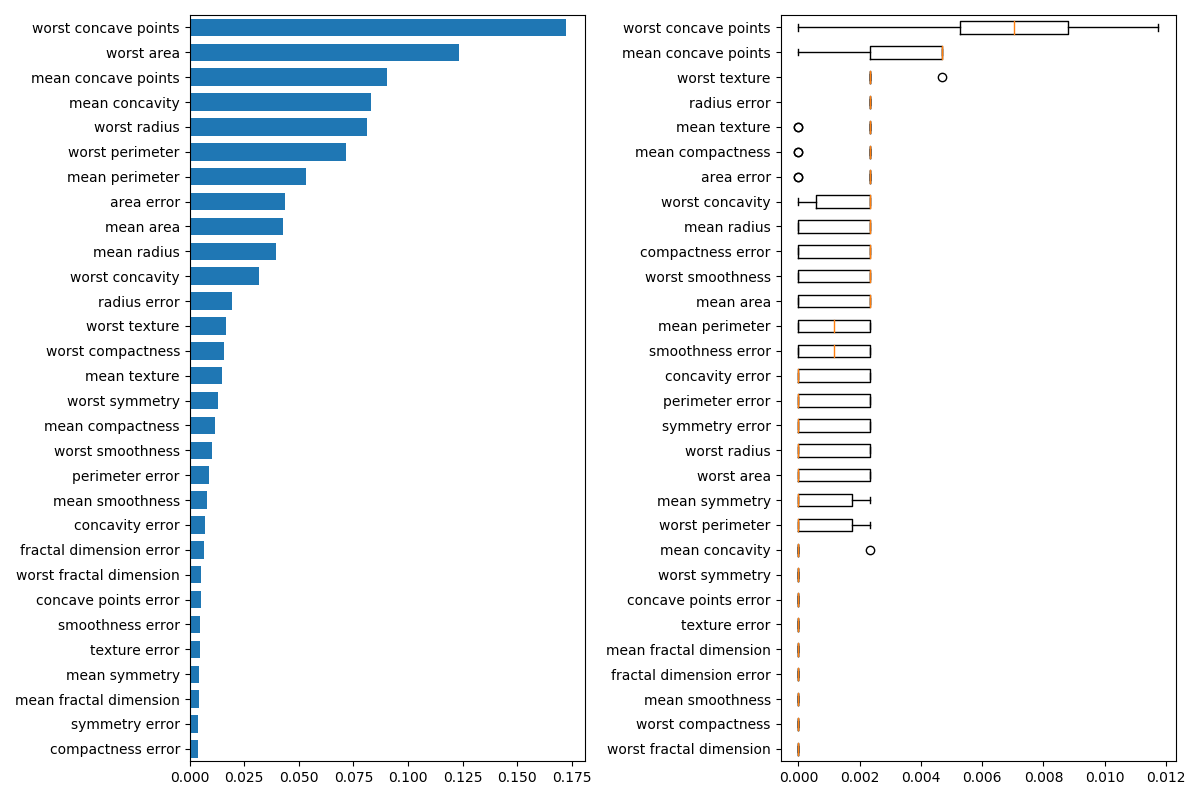
处理多重共线性特征
当特征是共线特征时,置换一个特征对模型性能的影响很小,因为它可以从相关特征中获得相同的信息。
处理多线性特征的一种方法是对Spearman秩序相关性执行分层聚类,选择一个阈值,并从每个聚类中保留一个特征。首先,我们绘制了相关特征的热图:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 8))
corr = spearmanr(X).correlation
corr_linkage = hierarchy.ward(corr)
dendro = hierarchy.dendrogram(corr_linkage, labels=data.feature_names, ax=ax1,
leaf_rotation=90)
dendro_idx = np.arange(0, len(dendro['ivl']))
ax2.imshow(corr[dendro['leaves'], :][:, dendro['leaves']])
ax2.set_xticks(dendro_idx)
ax2.set_yticks(dendro_idx)
ax2.set_xticklabels(dendro['ivl'], rotation='vertical')
ax2.set_yticklabels(dendro['ivl'])
fig.tight_layout()
plt.show()
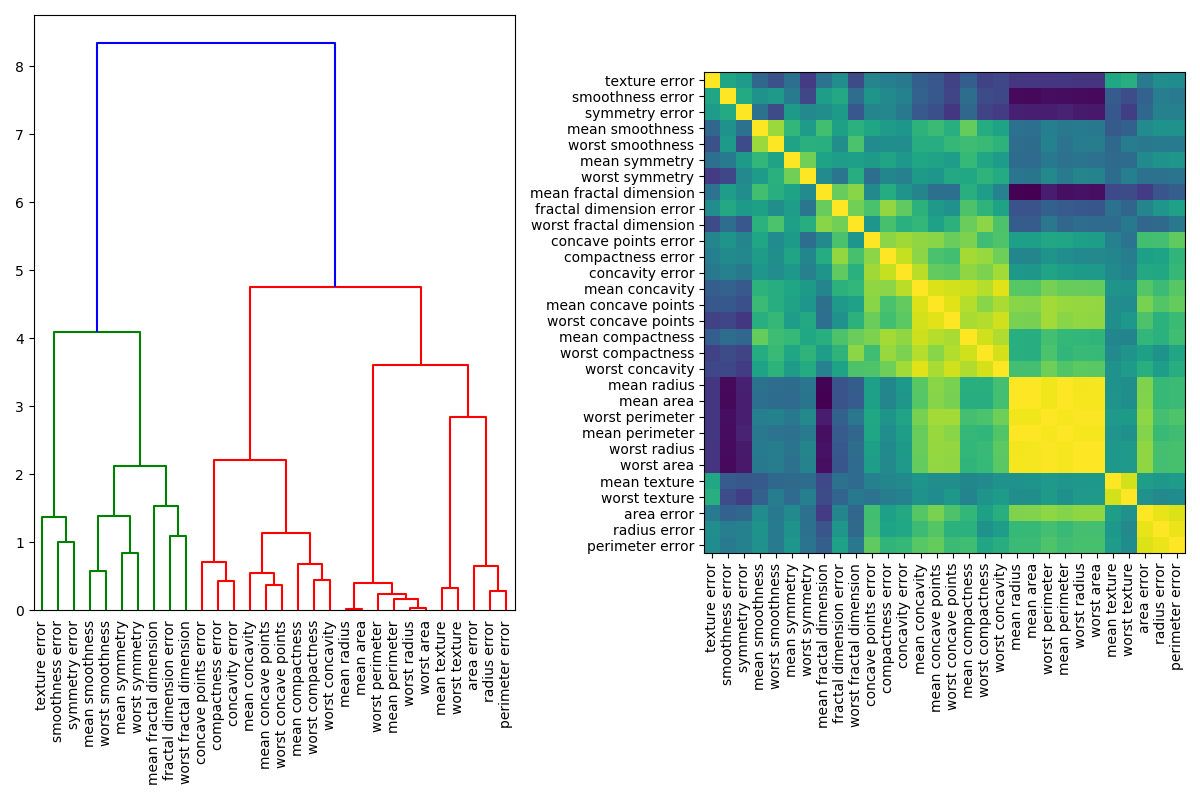 接下来,我们通过对树状图的可视化检查来手动选择一个阈值,将我们的特征分组成簇,并从每个簇中选择一个特征来保存,从我们的数据集中选择这些特征,并训练一个新的随机森林。与在完整数据集上训练的随机林相比,新随机林的测试精度变化不大。
接下来,我们通过对树状图的可视化检查来手动选择一个阈值,将我们的特征分组成簇,并从每个簇中选择一个特征来保存,从我们的数据集中选择这些特征,并训练一个新的随机森林。与在完整数据集上训练的随机林相比,新随机林的测试精度变化不大。
Accuracy on test data with features removed: 0.97
脚本的总运行时间:(0分6.505秒)
Download Python source code:plot_permutation_importance_multicollinear.py
Download Jupyter notebook:plot_permutation_importance_multicollinear.ipynb

